2025
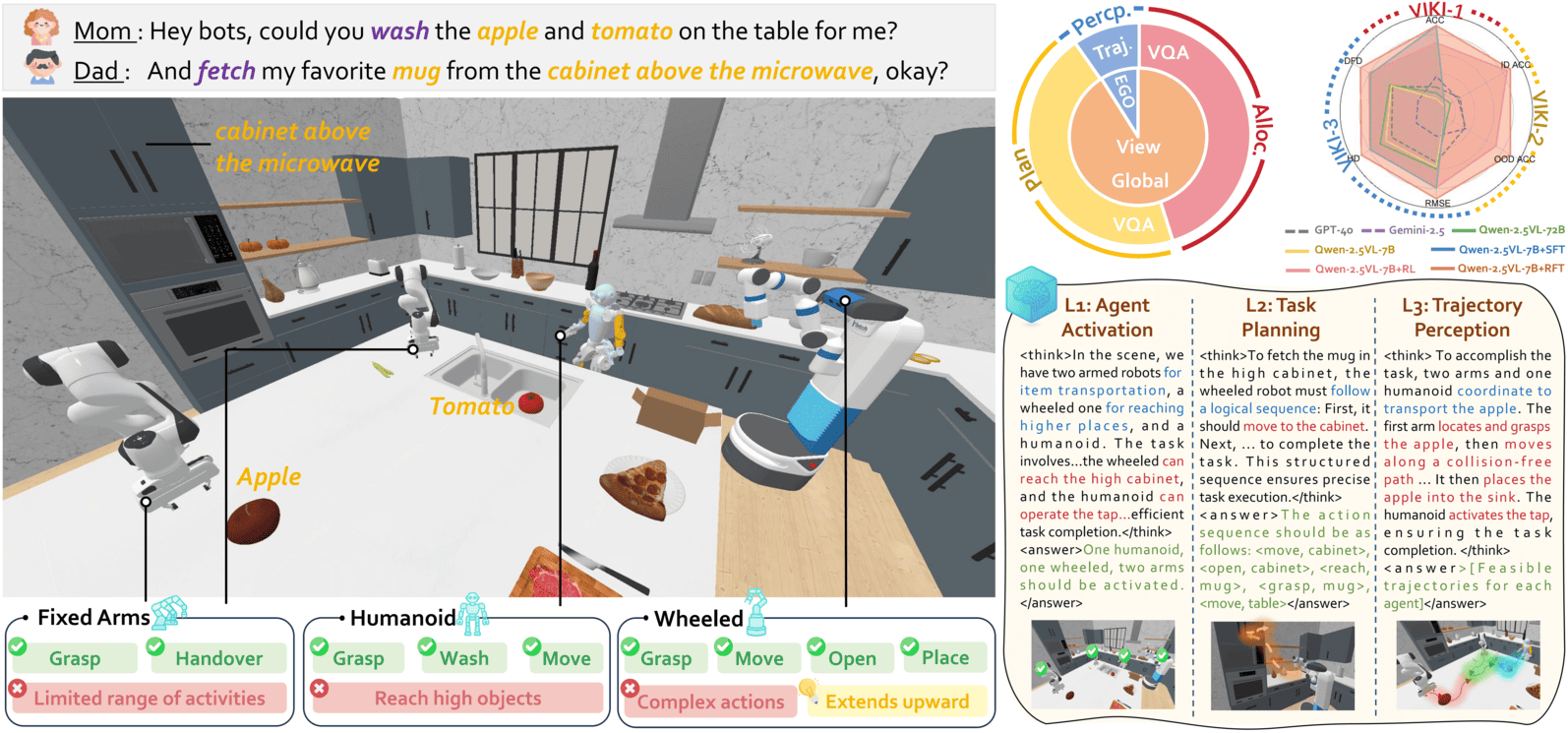
Viki-r: Coordinating embodied multi-agent cooperation via reinforcement learning
Li Kang*, Xiufeng Song*, Heng Zhou*, Yiran Qin, Jie Yang, Xiaohong Liu, Philip Torr, Lei Bai, Zhenfei Yin# (* equal contribution, # corresponding author)
Neural Information Processing Systems (NeurIPS) Benchmark 2025
Viki-r: Coordinating embodied multi-agent cooperation via reinforcement learning
Li Kang*, Xiufeng Song*, Heng Zhou*, Yiran Qin, Jie Yang, Xiaohong Liu, Philip Torr, Lei Bai, Zhenfei Yin# (* equal contribution, # corresponding author)
Neural Information Processing Systems (NeurIPS) Benchmark 2025

Robofactory: Exploring embodied agent collaboration with compositional constraints
Yiran Qin*, Li Kang*, Xiufeng Song*, Zhenfei Yin, Xiaohong Liu, Xihui Liu, Ruimao Zhang, Lei Bai# (* equal contribution, # corresponding author)
International Conference on Computer Vision (ICCV) 2025 Best Paper Award at CVPR 2025 MEIS Workshop
Robofactory: Exploring embodied agent collaboration with compositional constraints
Yiran Qin*, Li Kang*, Xiufeng Song*, Zhenfei Yin, Xiaohong Liu, Xihui Liu, Ruimao Zhang, Lei Bai# (* equal contribution, # corresponding author)
International Conference on Computer Vision (ICCV) 2025 Best Paper Award at CVPR 2025 MEIS Workshop